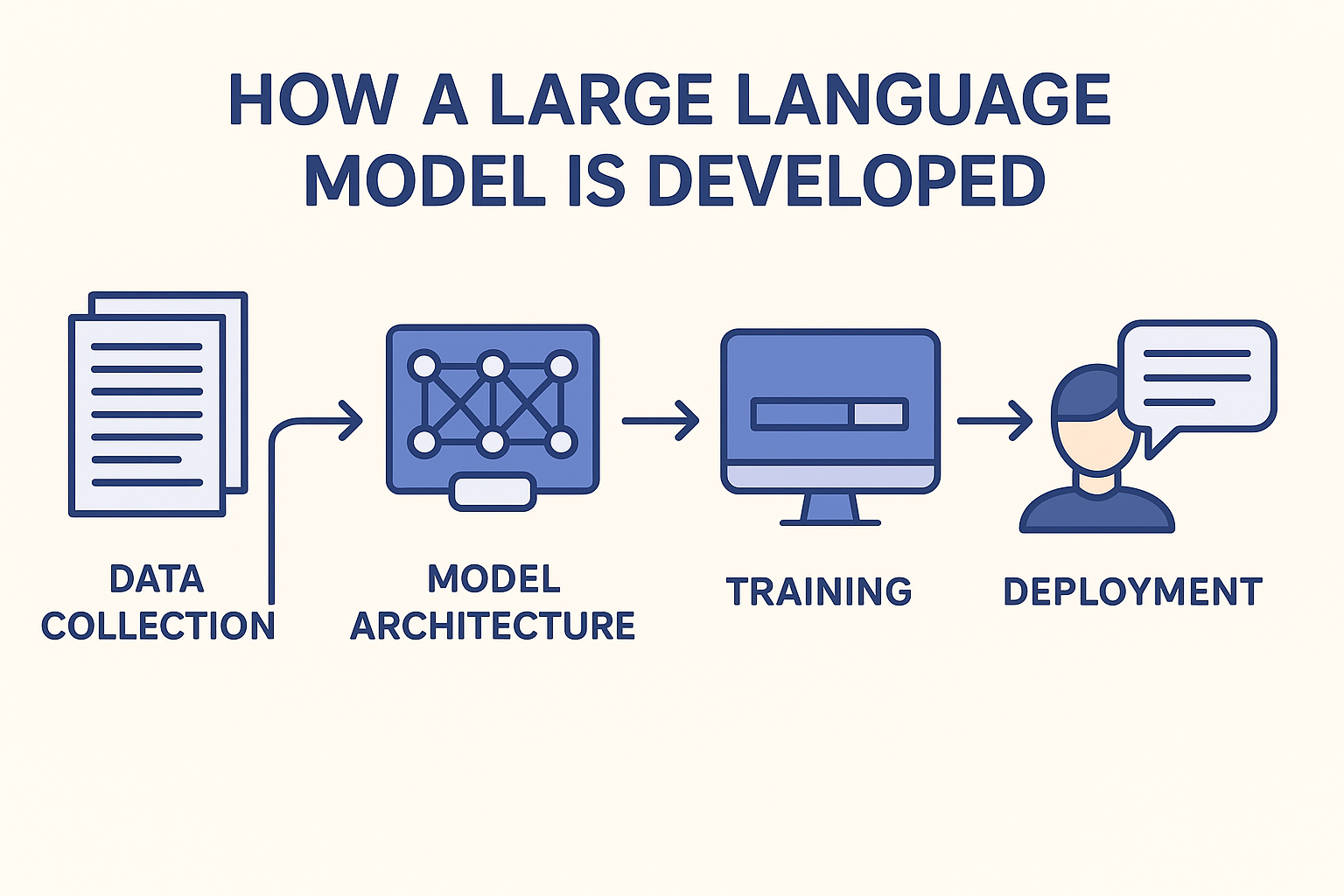
Kecerdasan buatan (AI) telah berkembang dari bidang riset khusus menjadi kekuatan transformatif yang mengubah industri, masyarakat, bahkan rutinitas pribadi sehari-hari. Di antara inovasi paling berpengaruh adalah large language model (LLM)—sistem seperti GPT, Claude, atau LLaMA yang mampu membaca, menulis, meringkas, menerjemahkan, hingga melakukan penalaran yang bernuansa.
Namun di balik pengalaman pengguna yang mulus, tersembunyi upaya teknis dan manusia yang sangat besar. Mengembangkan LLM melibatkan matematika, ilmu komputer, linguistik, rekayasa data, desain infrastruktur, serta etika. Proses ini adalah perpaduan antara teori dan praktik, membutuhkan keputusan hati-hati di setiap tahap: mulai dari menetapkan tujuan, mengumpulkan data pelatihan, merancang arsitektur, melatih dalam skala besar, hingga menangani persoalan sosial seperti bias, penyalahgunaan, dan transparansi.
Artikel ini menjelaskan secara mendalam, langkah demi langkah, bagaimana sebuah LLM dikembangkan—dari fondasi konseptual hingga penerapan dan perbaikan berkelanjutan.
1. Fondasi LLM
1.1 Apa Itu Language Model?
Pada dasarnya, model bahasa adalah sistem statistik yang memprediksi kata (atau token) berikutnya dalam sebuah urutan berdasarkan konteks sebelumnya. Misalnya:
- Input: “Kucing itu duduk di atas ___”
- Output: “karpet” (dengan probabilitas tinggi).
Model tradisional menggunakan n-gram (prediksi berbasis urutan kata dengan panjang tetap). Namun pendekatan ini sangat terbatas: tidak bisa menangani dependensi panjang, kurang generalisasi, dan membutuhkan memori besar untuk menyimpan probabilitas.
Terobosan datang dengan jaringan saraf (neural network), khususnya arsitektur transformer (diperkenalkan dalam makalah “Attention Is All You Need” tahun 2017). Transformer memungkinkan model menangkap hubungan jangka panjang melalui mekanisme self-attention, sehingga dapat diskalakan hingga miliaran bahkan triliunan parameter.
1.2 Mengapa Disebut “Large”?
Sebuah model disebut “besar” bila jumlah parameternya (bobot yang dapat dipelajari) melebihi ratusan juta atau miliaran. Skala penting karena:
- Kapasitas: Model besar dapat merepresentasikan pola yang lebih kompleks.
- Perilaku emergen: Pada skala tertentu, model menunjukkan kemampuan baru yang tidak ada pada model kecil (misalnya few-shot reasoning).
- Generalisasi: Dengan data pelatihan yang beragam, model besar dapat beradaptasi lintas tugas tanpa pemrograman eksplisit.
1.3 Prinsip Panduan dalam Pengembangan
Pengembangan LLM mengikuti beberapa prinsip utama:
- Hukum skala: Peningkatan data, ukuran model, dan komputasi memberikan peningkatan kinerja yang dapat diprediksi (hingga batas tertentu).
- Transferabilitas: Latih dengan data umum terlebih dahulu, kemudian adaptasi ke domain tertentu melalui fine-tuning.
- Human-AI alignment: Pastikan model berperilaku aman, jujur, dan sesuai dengan maksud pengguna.
2. Menentukan Tujuan dan Kebutuhan
Sebelum pengembangan dimulai, tim menetapkan tujuan dan cakupan LLM.
- Umum vs. spesialis: Apakah model dimaksudkan untuk asisten percakapan umum (seperti GPT) atau difokuskan pada domain tertentu (misalnya dokumen hukum, riset ilmiah, atau pengetahuan medis)?
- Target performa: Menentukan tolok ukur, seperti akurasi dalam pemahaman bahasa, ketahanan terhadap input berbahaya, atau efisiensi saat inferensi.
- Pertimbangan etis: Merancang pedoman untuk meminimalkan keluaran berbahaya, melindungi privasi, dan menjaga transparansi.
- Batasan sumber daya: Melatih model besar membutuhkan komputasi dan energi sangat besar. Tim harus menyeimbangkan ambisi dengan biaya dan kelayakan.
Keputusan awal ini akan menentukan semua langkah berikutnya: pemilihan dataset, desain arsitektur, kebutuhan infrastruktur, hingga langkah keamanan.
3. Pengumpulan dan Persiapan Data
3.1 Data sebagai Fondasi
LLM hanya sebaik data tempat ia belajar. Dari data inilah model menyerap tata bahasa, fakta, pola penalaran, hingga nuansa gaya bahasa.
Sumber data biasanya meliputi:
- Data web publik (artikel, forum, situs).
- Buku digital dan makalah akademis.
- Transkrip audio atau video.
- Data multibahasa untuk pemahaman lintas bahasa.
3.2 Tantangan dalam Pengumpulan Data
- Skala: LLM membutuhkan triliunan token. Mengumpulkan volume sebesar ini memerlukan perayap web (crawler) dalam skala besar.
- Kualitas: Tidak semua teks online akurat, sopan, atau bermanfaat. Data buruk menghasilkan keluaran buruk.
- Keberagaman: Agar tidak bias sempit, data harus mencakup berbagai domain, budaya, dan bahasa.
- Isu hukum dan etika: Hak cipta, izin, dan privasi harus dihormati.
3.3 Pembersihan dan Penyaringan
Data mentah dari web penuh kebisingan. Proses preprocessing meliputi:
- Menghapus duplikat, teks tidak relevan (iklan, menu), atau teks rusak.
- Menyaring konten berbahaya atau bias.
- Identifikasi bahasa untuk memastikan cakupan multibahasa.
- Deduplikasi agar model tidak terlalu menghafal teks berulang.
Pipeline modern menggunakan kombinasi heuristik, filter berbasis aturan, dan klasifikator pembelajaran mesin.
3.4 Tokenisasi
LLM tidak bekerja langsung dengan kata, melainkan dengan token—yang bisa berupa kata, sub-kata, atau karakter. Teknik seperti Byte Pair Encoding (BPE) atau SentencePiece membagi teks menjadi token secara efisien.
Contoh:
- Teks: “ketidakbahagiaan”
- Token: [“ketidak”, “bahagiaan”]
Tokenisasi memungkinkan penanganan kata langka atau baru sekaligus menjaga beban komputasi tetap terkendali.
4. Arsitektur Model
4.1 Tulang Punggung Transformer
Hampir semua LLM modern dibangun di atas arsitektur transformer, yang terdiri dari:
- Embedding layer: Mengubah token menjadi vektor.
- Self-attention mechanism: Membuat setiap token “memperhatikan” token lain, menangkap konteks.
- Feedforward network: Melakukan transformasi non-linear.
- Residual connection & normalisasi: Menstabilkan pelatihan.
- Lapisan bertumpuk: Puluhan hingga ratusan lapisan membangun pemahaman mendalam.
4.2 Mekanisme Atensi
Self-attention menghitung hubungan antar token dalam satu urutan. Untuk setiap token, ia menjawab: “Token lain mana yang harus saya fokuskan?” Inilah yang memungkinkan model menangkap hubungan jangka panjang yang sulit dicapai arsitektur lama.
4.3 Pertimbangan Skala
- Kedalaman vs. lebar: Trade-off antara menambah jumlah lapisan (kedalaman) atau memperbesar ukuran lapisan (lebar).
- Paralelisasi: Membagi komputasi ke banyak GPU/TPU dengan data parallelism dan model parallelism.
- Model sparse: Teknik seperti Mixture-of-Experts (MoE) mengurangi komputasi dengan hanya mengaktifkan sebagian model untuk setiap input.
4.4 Varian dan Penyempurnaan
Beberapa varian populer:
- Decoder-only model (misalnya GPT).
- Encoder-decoder model (misalnya T5, BERT untuk pemahaman dan generasi).
- Retrieval-augmented model yang menggabungkan LLM dengan basis data eksternal untuk akurasi faktual.
5. Melatih Model
5.1 Fungsi Objektif
Tujuan utama pelatihan adalah prediksi token berikutnya. Model belajar dengan meminimalkan cross-entropy loss antara distribusi probabilitas prediksi dan token sebenarnya.
Meski tampak sederhana, tujuan ini melahirkan kemampuan luar biasa: tata bahasa, ingatan fakta, ringkasan, penalaran—semua muncul dari latihan memprediksi token berikutnya dalam pustaka teks masif.
5.2 Alur Pelatihan
- Inisialisasi: Bobot diatur secara acak.
- Forward pass: Token masuk ke model, menghasilkan prediksi.
- Perhitungan loss: Bandingkan prediksi dengan kebenaran.
- Backward pass: Hitung gradien dengan backpropagation.
- Optimasi: Perbarui bobot dengan algoritma seperti AdamW.
- Iterasi: Ulangi miliaran kali sepanjang batasan waktu.
5.3 Kebutuhan Infrastruktur
Melatih LLM adalah tantangan logistik besar:
- Hardware: Ribuan GPU/TPU dengan memori besar.
- Jaringan: Koneksi cepat dan latensi rendah (InfiniBand, NVLink).
- Penyimpanan: Petabyte untuk dataset dan checkpoint.
- Energi: Pelatihan GPT-3 menghabiskan ribuan megawatt-jam.
5.4 Dinamika Pelatihan
- Curriculum learning: Memberi data bertahap, dari sederhana ke kompleks.
- Checkpointing: Menyimpan status sementara untuk pemulihan.
- Monitoring: Melacak metrik (kurva loss, perplexity) untuk stabilitas.
6. Evaluasi dan Benchmark
6.1 Benchmark Standar
LLM diuji dengan tolok ukur seperti:
- GLUE/SuperGLUE: Tugas pemahaman bahasa alami.
- MMLU: Pemahaman lintas domain.
- BIG-bench: Evaluasi umum berskala luas.
6.2 Evaluasi Manusia
Karena benchmark tidak cukup, peninjau manusia menilai:
- Koherensi jawaban.
- Akurasi faktual.
- Kreativitas.
- Keamanan (menghindari keluaran berbahaya).
6.3 Kemampuan Emergen
Pada skala besar, muncul kemampuan mengejutkan:
- Few-shot learning.
- Penalaran berantai (chain-of-thought).
- Penerjemahan tanpa supervisi eksplisit.
7. Fine-Tuning dan Alignment
7.1 Supervised Fine-Tuning (SFT)
Model disempurnakan dengan data kurasi (misalnya pasangan instruksi–jawaban). Ini membantu model menyesuaikan diri dengan tugas tertentu.
7.2 Reinforcement Learning with Human Feedback (RLHF)
Metode penting yang melibatkan:
- Mengumpulkan keluaran model dan memberi peringkat dengan preferensi manusia.
- Melatih reward model untuk memprediksi peringkat manusia.
- Menggunakan reinforcement learning (misalnya PPO) agar LLM menghasilkan keluaran yang lebih baik.
7.3 Constitutional AI dan Alternatif
Beberapa pendekatan mengganti atau melengkapi RLHF dengan “AI feedback” berdasarkan prinsip atau konstitusi (aturan). Ini mengurangi ketergantungan pada anotator manusia.
8. Keamanan, Etika, dan Tata Kelola
8.1 Bias dan Keadilan
LLM bisa mencerminkan bias dari data. Pengembang harus mendeteksi dan mengurangi:
- Stereotip.
- Konten merugikan atau ofensif.
- Performa yang tidak setara antar kelompok.
8.2 Privasi dan Keamanan
Diperlukan mekanisme agar model tidak membocorkan data sensitif atau disalahgunakan (misalnya phishing, disinformasi).
8.3 Transparansi
Dokumentasi jelas (seperti model card atau data statement) menjelaskan kemampuan, risiko, dan keterbatasan.
8.4 Tata Kelola
Pembuat kebijakan dan organisasi membahas regulasi untuk menyeimbangkan inovasi dan keselamatan.
9. Penerapan dan Penyajian
9.1 Kompresi Model
Model mentah terlalu besar dan mahal untuk dipakai sehari-hari. Teknik seperti quantization, pruning, dan distillation mengecilkan model tanpa banyak kehilangan performa.
9.2 Optimisasi Inferensi
- Batching request untuk meningkatkan throughput.
- Caching attention state agar respons lebih cepat.
- Hardware khusus untuk akselerasi inferensi.
9.3 API dan Antarmuka
Model biasanya disediakan melalui API, memungkinkan integrasi ke aplikasi—chatbot, alat produktivitas, asisten kode—dengan kontrol terpusat.
10. Perbaikan Berkelanjutan
Pengembangan LLM tidak pernah benar-benar selesai. Setelah diterapkan, dilakukan:
- Monitoring penggunaan nyata untuk mendeteksi pola berbahaya.
- Mengumpulkan umpan balik pengguna untuk perbaikan.
- Memperbarui dengan data baru agar tetap relevan.
- Meneliti metode pelatihan baru yang lebih efisien.
11. Studi Kasus
11.1 GPT-3
- 175 miliar parameter.
- Dilatih dengan ~500 miliar token.
- Membutuhkan ribuan GPU selama berminggu-minggu.
- Menunjukkan kemampuan few-shot learning yang revolusioner.
11.2 PaLM
- 540 miliar parameter.
- Dilatih multibahasa dan multimodal.
- Memperlihatkan penalaran yang kuat.
11.3 LLaMA
- Fokus pada efisiensi: ukuran lebih kecil (7–65B) dengan data berkualitas tinggi.
- Bobot model dibuka untuk riset.
12. Arah Masa Depan
- Multimodalitas: Menggabungkan teks, gambar, audio, video untuk pemahaman lebih kaya.
- Efisiensi: Pelatihan dengan komputasi lebih sedikit dan berkelanjutan.
- Personalisasi: Menyesuaikan model untuk pengguna tanpa mengorbankan privasi.
- Otonomi: LLM sebagai agen yang bisa merencanakan, bertindak, dan menggunakan alat.
- Kerangka tata kelola: Standar internasional untuk penerapan yang bertanggung jawab.
Kesimpulan
Mengembangkan model bahasa besar (LLM) adalah salah satu pencapaian teknik dan sains paling kompleks di era ini. Ia mencakup banyak disiplin—dari pengumpulan data dan matematika hingga etika dan kebijakan publik. Prosesnya memerlukan daya komputasi besar sekaligus penilaian manusia yang bijak, dengan setiap tahap menghadirkan tantangan tersendiri.
Namun hasilnya luar biasa: mesin yang bisa berinteraksi dengan bahasa — aspek paling manusiawi—dengan kefasihan dan fleksibilitas. Seiring evolusi LLM, masyarakat menghadapi tantangan ganda: memanfaatkan potensinya untuk kemajuan sekaligus mengendalikan risikonya.
Dengan kata lain, kisah pengembangan LLM bukan hanya tentang mesin yang belajar dari manusia—tetapi juga tentang manusia yang belajar bagaimana membangun, membimbing, dan hidup berdampingan dengan sistem cerdas secara bertanggung jawab.
image generated with ChatGPT